
Микросхемы ПЛИС Speedster22i от Achronix: самые быстрые и самые большие. Часть 1
Введение
Безусловно, на рынок ПЛИС приходят новые игроки. Например, в 2006 году появилась фирма SiliconBlue [1]. Это была фаблесс-компания, производившая свои ультрамалопотребляющие ПЛИС — mobileFPGA по 65‑нм техпроцессу на TSMC. Но появление данной фирмы практически никакого влияния на рынок ПЛИС в целом не оказало. Не произошло этого потому, что ее продукция выпускалась на том же самом TSMC и по тем же технологиям, что и продукция конкурентов. В итоге в 2012 году фирма SiliconBlue была поглощена фирмой Lattice.
Так что же, рынок ПЛИС столь незыблем? Или что-то способно его изменить? Как известно, в горах маленький камешек, падая со склона, может породить большую лавину. И здесь роль такого маленького камешка сыграли гаджеты. Именно гаджеты вызвали лавину спроса на мобильные приложения и тем самым изменили рынок ПЛИС.
Бурный рост рынка гаджетов и ноутбуков привел к падению продаж настольных компьютеров. Причем настолько, что у ведущего производителя процессоров для настольных компьютеров — фирмы Intel возник определенный спад, который привел к недогрузке производственных линий. Как мы помним, ранее Intel не так сильно тревожилась из-за подобных проблем. Но сейчас в секторе рынка производителей микросхем тоже грядут перемены. Близится переход с кремниевых пластин диаметром 300 мм на пластины диаметром 450–500 мм. Это повысит расходы на строительство фабрик и производственное оборудование, но одновременно и удешевит микросхемы. А значит, гаджеты станут еще доступнее. И отсюда следует самый главный вывод. Фирма Intel заинтересована в ускоренной амортизации оборудования и предложила свои производственные мощности фаблесс-компаниям. Далее не трудно «сложить пазл». Большие процессорные корпуса, миллионы вентилей на кристалле по новейшим проектным нормам, много сотен выводов. Желательно получить в производство кристалл с регулярной структурой, типа памяти. А уж память — любимая продукция Intel, которую фирма умела производить еще в «допроцессорную эру». Так кого же выбрала Intel? Или, скажем так, кто же выбрал Intel как свою фабрику? Конечно, фирма, которая решилась производить ПЛИС! Вот о ее продукции и пойдет речь в нашей статье.
Итак, тихая идиллия на рынке ПЛИС была нарушена небольшой, но амбициозной компанией, предложившей альтернативу ПЛИС Xilinx и Altera, и сразу в категории Hi-End. По оценке Electronic Enjeneering Journal [2], с появлением третьего производителя рынок ПЛИС никогда не будет прежним, а конечный потребитель получит существенную выгоду от расширения конкуренции.
Американская компания Achronix [3] — самый молодой производитель ПЛИС — основана в 2004 году группой специалистов из Корнельского университета, к которой присоединились ветераны компаний Intel, Altera и Xilinx. Это фаблесс-компания, которая работает в стратегическом союзе с Intel и выпускает свои микросхемы на заводах Intel. Начав с 180‑нм техпроцесса, к настоящему времени компания изготавливает свои ПЛИС по самому современному 22‑нм техпроцессу Intel Tri-Gate и намерена перейти на 14‑нм, а в дальнейшем и на 10‑нм техпроцесс (рис. 1).

Рис. 1. Этапы перехода на новые технологические нормы для микросхемы Speedster22i HD1000
ПЛИС Speedster22i (рис. 2) выпускаются непосредственно на заводах Intel, расположенных в США. Семейство Speedster22i нацелено на сегмент высокопроизводительных ПЛИС и схем для высокоскоростных сетевых устройств. По сравнению с традиционными изготовителями конкурентным преимуществом этих микросхем является как разумная (для сегмента Hi-End) цена ПЛИС, так и широкий набор аппаратных IP-ядер, включая ядра DDR‑3, PCI-express v3, Interlaken и 10/40/100G Ethernet MAC. На данный момент начат выпуск семейства ПЛИС категории Hi-End Speedster22i с рабочей частотой LUT до 750 МГц и производительностью Serdes по 12,75 Гбит/с на канал и 28 Гбит/с на канал в Speedster22i HD1500.

Рис. 2. Топология микросхемы Speedster22i HD1000
Великий полководец Наполеон Бонапарт говорил, что сражения всегда выигрывают только «большие батальоны». Так вот, для ПЛИС сегмент Hi-End — это действительно «большие батальоны». И тут все немного не так, как в привычных нам среднеценовых ПЛИС. Давайте рассмотрим ситуацию подробнее. Фирма Xilinx, например, чтобы перейти рубеж в миллион LUT, научилась делать микромодули, то есть сборки из нескольких кристаллов со сквозными цепями между ними. И это «правый край» для их седьмой серии. А вот для Speedster22i на миллион LUT — это не край, а только середина серии, потому как уже на подходе Speedster22i HD1500 с его 1,75 млн LUT.
А за этим следуют и другие очевидные вещи. Нам понятно, что какая-нибудь «железяка» для болида «Формулы‑1» или колесо для карьерного грузовика стоит больших денег. То же самое и для ПЛИС. Для «тяжеловесов» и программное обеспечение «весит» больше. И даже не в денежном плане, не об этом речь. Для компиляции «тяжелых» проектов нужны самые производительные компьютеры и очень много оперативной памяти. Для высокоскоростных каналов передачи информации, например, таких как Ethernet 10/40/100 Гбит/с, тоже требуется довольно дорогое оборудование. Да, затраты велики, но и выигрыш внушителен. Ведь рано или поздно все те, кто не перешел на самые быстрые микросхемы ПЛИС, не выдержат гонку за быстродействие.
Ну а теперь давайте рассмотрим архитектуру микросхем — этому посвящена первая часть статьи, а затем перейдем к периферии, программным инструментам и стартовым наборам.
Сайт компании
Сайт компании [3, 4] представлен на английском и русском языках. Там приводится информация о самой компании, о ее продукции, а также размещены новости и статьи.
Сразу же хочется отметить следующее. Все выложенные документы можно получить свободно, никаких ограничений типа NDA не требуется. Большая часть документации — на английском, хотя некоторые файлы уже переведены на русский на русскоязычном же сайте. Также имеются видеоролики, из них наибольший интерес представляют те, в которых показаны испытания стартового набора при проверке аппаратных IP-контроллеров и программных инструментов:
- Обзор программного обеспечения Achronix CAD Environment (ACE).
- Лабораторные испытания PCI Express.
- Лабораторные испытания 10G Ethernet.
- Лабораторные испытания передачи SerDes.
- Лабораторные испытания приема SerDes.
- Лабораторные испытания отладчика Snapshot Debugger.
Спецификации приводятся как на программные инструменты и микросхемы, так и на отдельные части этих микросхем, а именно на все аппаратные IP-блоки. В спецификациях есть подробные описания блоков. Для конфигурации IP-блоков в программных инструментах предусмотрены визарды. В тех же «даташитах» предлагаются подробные описания методики конфигурации визардов, выполняемой в программных инструментах.
Программные инструменты
Отдельный раздел сайта посвящен программным инструментам. Среда разработки компании Achronix — ACE использует для синтеза внешние стандартные синтезаторы. ACE поставляется с уже оптимизированными версиями Synplify-Pro от компании Synopsys или Precision Synthesis от Mentor Graphics. Для симуляции применяются ModelSim от Mentor Graphics, VCS от Synopsys и Riviera от Aldec. Проектирование ведется на стандартных языках Verilog и VHDL. Это без особых усилий позволяет инженерам переводить уже имеющиеся разработки на платформу Achronix Speedster22i.
Демонстрационная лицензия на программное обеспечение предоставляется на три месяца по запросу.
Продукция компании Achronix в России
В России продукция компании поставляется через официальное представительство Achronix, компанию «Лаборатория высокопропускных СБИС» [4, 5]. Сейчас оно осуществляет поставки ПЛИС Speedster22i HD680 и HD1000, а также отладочных плат HD1000 development kit, предназначенных для разработки сложных и высокопроизводительных устройств, включая те, которые функционируют на 100G Ethernet. Об этом стартовом наборе автор планирует написать в дальнейшем. Также представительство осуществляет квалифицированную техническую поддержку заказчиков на всех этапах разработки и производства продукции. Но, как говорится, хочется не только почитать, но и хоть один раз попробовать. Именно поэтому представительство и компания «Лаборатория высокопропускных СБИС» работают над проектом виртуального стартового набора. Таким образом, довольно скоро можно будет взять свой «боевой» проект, заменить в нем примитивы, связанные с «родословной» изготовителя микросхем, и запустить в удаленном режиме компиляцию проекта для Speedster22i HD1000. И посмотреть, что получится в итоге.
Архитектура ПЛИС Achronix семейства Speedster22i HD
Микросхемы семейства Speedster22i HD [6], работающие на максимальной частоте до 750 МГц, имеют эффективную плотность до 1,7 млн LUT. Они выполнены по 22‑нм техпроцессу на фабрике Intel. Конфигурационные ячейки микросхем созданы на основе памяти SRAM, поэтому они не имеют энергонезависимой памяти конфигурации и могут быть полностью реконфигурируемыми при каждом включении или во время работы. Логические ячейки выполнены как стандартный синхронный блок с 4 входами LUT.
У реконфигурируемого логического блока (RLB) десять LUT и десять регистров. Микросхемы также содержат блочные памяти RAM. Каждая блочная память RAM имеет объем 80 кбит и представляет собой двух-портовую память.
Часть микросхемы, отвечающая за ввод/вывод сигналов, содержит встроенные IP-контроллеры, конфигурируемые стандартные входы/выходы (I/O), высокоскоростные блоки последовательной передачи данных SerDes, блоки генераторов синхрочастоты со схемами фазовой автоподстройки частоты (PLL) и логику, требуемую для конфигурации микросхемы. Микросхема включает до 64 узлов SerDes, работающих на скорости до 12,75 Гбит/с, до 16 узлов SerDes на 28 Гбит/с и еще до 996 высокоскоростных реконфигурируемых I/O. Дополнительный выделенный аппаратный IP-узел предусматривает:
- до шести DDR2/3‑трансиверов и контроллеров;
- до 48 контроллеров Ethernet на 10 Гбит/с;
- до 12 контроллеров Ethernet на 40 Гбит/с;
- до четырех контроллеров Ethernet на 100 Гбит/с.
Также есть до четырех контроллеров сети Interlaken и два контроллера PCI, все они реализованы как встроенные аппаратные IP-ядра и поэтому не используют логику микросхемы, имеют максимальную производительность и не накладывают на линии коммутации внутри микросхемы никаких дополнительных требований по синхронизации.
Кроме того, имеются выделенные выводы микросхемы для встроенного программирования и конфигурации (CFG), которая выполняется различными способами. Выделенные контакты ввода/вывода синхрочастоты располагаются около каждого угла микросхемы. На рис. 3 показана схема расположения блоков в микросхеме Speedster22i.

Рис. 3. Схема расположения блоков в микросхеме Speedster22i HD 1000
Семейство ПЛИС HD
Семейство ПЛИС Achronix Speedster22i HD представлено тремя микросхемами: HD680, HD1000 и HD1500. Характеристики микросхем указаны в таблице 1. Внешний вид микросхем семейства Speedster22i HD дан на рис. 4.

Рис. 4. Микросхема Speedster22i HD1000
|
Параметры |
HD680 |
HD1000 |
HD1500 |
|
Объем логики, включая аппаратные контроллеры (эффективных ячеек LUT) |
660 000 |
1 045 000 |
1 725 000 |
|
Объем программируемой логики (в LUT) |
400 000 |
700 000 |
1 100 000 |
|
Количество модулей BRAM |
600 |
1026 |
1728 |
|
Количество модулей LRAM |
4320 |
6156 |
10 368 |
|
Объем 80-килобитных BRAM |
48 000 |
82 080 |
138 240 |
|
Объем 640-битных LRAM (всего кбит) |
2765 |
3940 |
6636 |
|
Умножителей/MACs (28×28) |
240 |
756 |
864 |
|
Количество линий SerDes 12,75 Гбит/с |
40 |
64 |
48 |
|
Количество линий SerDes 28 Гбит/с |
– |
– |
16 |
|
Аппаратных контроллеров Ethernet (MAC-уровень) 10/40/100 Гбит/с |
2 |
2 |
4 |
|
Контроллеров Interlaken LLC |
1 |
2 |
4 |
|
Контроллеров PCI Express LLC |
1 |
2 |
2 |
|
Контроллеров DDR2/DDR3 |
4 |
6 |
6 |
|
Количество PLL |
16 |
16 |
16 |
|
FBGA2601 (52,5×52,5 мм): 12G 28G GPIO |
– – – |
64 0 960 |
48 16 960 |
|
FBGA1936 (45×45 мм): 12G 28G GPIO |
40 0 684 |
40 0 684 |
20 4 684 |
|
FBGA1520 (40×40 мм): 12G 28G GPIO |
18 0 684 |
– – – |
– – – |
Примечание. Шаг контактов (ball pitch) — 1 мм.
Прежде чем приступить к дальнейшему описанию микросхем, необходимо сделать небольшое отступление.
Разработчики компьютеров давно применяют «географическую» систему обозначений в своих проектах. Это всем известные «северный» и «южный» мосты. В компании Achronix тоже принята «географическая» система обозначений областей кристалла. Верхняя область в их документации называется «северная», нижняя — «южная». Соответственно «западная» и «восточная» — это правая и левая область кристалла. И в нашей статье мы будем придерживаться терминологии, принятой в описаниях фирмы.
Аппаратные IP-ядра
Микросхемы Speedster22i имеют набор аппаратных контроллеров интерфейсов в пространстве ввода/вывода.
Буферы ввода/вывода общего назначения (GPIO) могут работать в однополярном и дифференциальных режимах на частотах до 2133 МГц. Линии SerDes функционируют на скоростях до 28 Гбит/с. Выводы микросхемы могут использоваться как стандартные GPIO, так и аппаратные контроллеры 10, 40 и 100 Гбит Ethernet, Interlaken, PCI Express 1, 2 и 3 поколений и контроллеры DDR3.
Преимущества аппаратных контроллеров интерфейсов:
- Расходуют всего 1/8 энергии, которую потребляли бы аналогичные контроллеры, реализованные на программируемой логике лучших ПЛИС конкурирующих производителей.
- Предоставляются без необходимости покупки дополнительных лицензий на использование.
- Работают с необходимой производительностью без каких-либо дополнительных усилий со стороны разработчика.
- Экономят время разработчика на оптимизации временных задержек, разводке и т. п. стандартной функциональности интерфейса, сокращая время выхода продукта на рынок и снижая риски.
Контроллеры 10/40/100-гигабитного Ethernet
Микросхемы Speedster22i включают до четырех независимых Ethernet MAC-контроллеров, позволяющих сократить энергопотребление и значительно упрощающих процесс разработки.
Контроллеры 10/40/100-гигабитного Ethernet MAC и PCS разработаны в полном соответствии со спецификацией IEEE P802.3ba draft 2.2.
Они могут использоваться для работы как в режиме сетевой карты, так и в коммутационных устройствах. Набор конфигурационных регистров позволяет как динамически настраивать контроллер для терминации и формирования MAC-фреймов, так и передавать MAC-фреймы без изменения в пользовательское устройство или в Ethernet-линию. Независимо от режима применения контроллер поддерживает объекты IEEE, IETF MIBII и RMON для устройств управления трафиком (SNMP).
Контроллеры канального MAC и PCS могут быть собраны в одну из следующих конфигураций:
- от 1 до 12 10‑гигабитных Ethernet-каналов;
- 1 100‑гигабитный канал + 1 или 2 10‑гигабитных канала;
- от 1 до 3 40‑гигабитных каналов;
- от 1 до 4 10‑гигабитных каналов + 1 или 2 40‑гигабитных канала;
- от 1 до 8 10‑гигабитных каналов + 1 40‑гигабитный канал.
Контроллеры DDR1/2/3
Микросхемы Speedster22i содержат до шести встроенных контроллеров DDR1/2/3, которые могут быть использованы для работы с микросхемами памяти DDR3 и модулями DIMM. Каждый контроллер DDR поддерживает работу по шине до 72 разрядов на скорости до 1866 Гбит/с (1066 МГц DDR). Контроллер и физический интерфейс действуют на частотах до 1066 МГц.
Контроллер DD3 поддерживает режим «авто» и custom. В режиме «авто» такие функции, как активация (activating)/предзарядка (precharging) банка/строки, запуск алгоритмов калибровки и последовательностей инициализации, проводятся незаметно для разработчика встроенным контроллером DDR. Назначение байтовых линий на выводы микросхемы выполняется незаметно для разработчика встроенным контроллером физического уровня (PHY) DDR. В режиме custom можно вручную переопределить такие функции, как автоматическое обновление и последовательности инициализации.
Interlaken
Interlaken — это масштабируемый интерфейс связи между микросхемами, разработанный для высоких скоростей передачи: от 10 до 100 Гбит в секунду и выше. Используя последние технологии SerDes и гибкий протокольный уровень, Interlaken минимизирует издержки энергопотребления и количество контактов. Одно из основных преимуществ Interlaken — его масштабируемость и гибкость в различных конфигурациях системы.
Микросхемы имеют встроенную полностью аппаратную поддержку Interlaken, отличающуюся высокой производительностью и низким энергопотреблением. Скорость портов SerDes может варьироваться от 4,6 до 12,5 Гбит/с.
PCI Express
Встроенные аппаратные контроллеры PCI Express микросхемы Achronix Speedster22i поддерживают все три уровня протокола (физический, канальный и транзакционный) в соответствии со стандартом PCI Express.
Основные технические характеристики контроллеров:
- Совместимость с базовой спецификацией PCI Express revision 3.0 version 0.9; обратная совместимость со стандартами PCI Express 2.1/2.0/1.1/1.0a.
- 1, 4 или 8 линий PCI Express.
- Поддержка скоростей: 8, 5 и 2,5 GT/s.
- Поддержка только режима конечного устройства (endpoint).
- Конвейеризируемый физический уровень (PHY).
- Поддержка как автономного, так и программно-управляемого выравнивания (equalization).
- Аппаратный DMA.
12.75G SerDes
Все микросхемы Speedster22i имеют встроенную поддержку SerDes для реализации различных протоколов. Микросхема содержит до шестидесяти четырех узлов SerDes, работающих на скорости до 12,75 Гбит/с, до шестнадцати SerDes на 28 Гбит/с.
Каждая линия SerDes может быть использована для связи:
- между микросхемами;
- через коммутационную плату;
- по кабелю.
Для передачи данных через коммутационную плату (или не витую пару) на скоростях более 5 Гбит/с предусмотрены дополнительные возможности, включая Transmit equalization и decision feedback equalization (DFE).
Ядро FPGA
Ядро микросхем Achronix Speedster22i HD содержит столбцы логики, памяти и умножители-аккумуляторы (BMAC), соединенные с линиями глобального межсоединения, как показано на рис. 2. Столбцы реконфигурируемых логических блоков (RLB) перемежаются столбцами блочной памяти (BRAM), локальной памяти (LRAM) и блоками умножителей-аккумуляторов (BMAC). Ядро также включает глобальные и локальные сети сигналов тактовых частот и сети сброса. Столбцы логики показаны на рис. 5.

Рис. 5. Столбцы RLB, BRAM, LRAM и BMAC в ядре микросхемы Speedster22i HD1000
Линии коммутации
Блоки RLB, BRAM, LRAM и BMAC соединяются универсальными глобальными линиями коммутации, по которым сигналы передаются между блоками. Сигналы коммутируются между вертикальными и горизонтальными дорожками маршрутизации. Входы и выходы от каждого блока RLB/BRAM/LRAM/BMAC соединяются с глобальными межсоединениями. В качестве примера на рис. 6 показан блок RLB с восемью входами и двумя выходами.

Рис. 6. Глобальные линии коммутации
Реконфигурируемый логический блок (RLB)
Реконфигурируемый логический блок (RLB) состоит из пяти логических кластеров, каждый из которых содержит два LUT и два регистра. В общей сложности это дает десять LUT с четырьмя входами в каждом RLB.
Есть два типа логических кластеров: простой логический кластер (LLC) и усиленный логический кластер (HLC). Их описание будет приведено далее. У каждого RLB есть три LLC и два HLC. У HLC есть большая функциональность, чем у LLC, поскольку он имеет усовершенствованную цепочку переноса, тогда как у LLC есть мультиплексор — MUX2. RLB показан на рис. 7. По существу, каждый RLB состоит из пяти логических кластеров, два из которых содержат цепочку переноса. Выделенные цепи для переноса, вход и выход позволяют каскадировать цепи переноса через несколько RLB.

Рис. 7. Реконфигурируемый логический блок
Эффективная обратная связь в RLB
Внутри RLB есть несколько механизмов обратной связи. То есть для того, чтобы получить эффективную обратную связь, сигналы обратной связи «заворачиваются» внутри RLB и не выводятся наружу, чтобы снова попасть на вход RLB, но уже через внешние ресурсы маршрутизации.
В RLB есть одна матрица, которая мультиплексирует следующие сигналы:
- Входные сигналы — входы RLB и сигналы внутренней обратной связи, поступающие к логическим кластерам.
- Выходные сигналы — выходы логических кластеров (защелкнутые на триггерах или не защелкнутые на триггерах) к выходам RLB, а также там, где требуется обратная связь, сигналы подаются к входам матрицы.
Прохождение сигналов обратной связи в RLB показано на рис. 8.

Рис. 8. Прохождение сигналов обратной связи в RLB
Оба выхода от каждого LUT, защелкнутые на триггерах или не защелкнутые на триггерах, могут также быть направлены от выходной матрицы назад, как сигналы обратной связи, во входную матрицу, непосредственно в RLB. Но если нужно, то выводы от RLB могут быть направлены назад на входы и через внешнюю маршрутизацию.
Логические кластеры
Легкий логический кластер (LLC) показан на рис. 9. Он содержит стандартный LUT с 4 входами — основной логический конструктивный блок структуры. Каждый LUT имеет четыре входа и один выход и может быть сконфигурирован так, чтобы на выходе выдать любое комбинаторное состояние функции входов (таблица истинности). Два LUT с четырьмя входами реализуют одну функцию LUT с пятью входами с использованием мультиплексора MUX2. Мультиплексор MUX2 может выполнять реализации определенных функций с шестью, семью, восемью и девятью входами. Мультиплексирование блоков (показанных на рис. 9) обеспечивает гибкий доступ к двум выводам регистра.

Рис. 9. Легкий логический кластер
Усиленный логический кластер (HLC) представлен на рис. 10. Большинство функций, возможных с легким логическим кластером, реализуется и в HLC. Кроме того, у каждого кластера есть 2‑разрядный сумматор, так же как и логика, необходимая для генерации арифметического сигнала переноса и распространения к HLC на «север» (вверх), к соответствующему входу RLB, и в передаче сигнала от его соседа на «юг» (то есть вниз).

Рис. 10. Усиленный логический кластер
Ресурсы памяти
Блочная память BRAM
Блочная память BRAM, находящаяся на кристалле Speedster22i, имеет объем 80 кбит и может работать как двухпортовая память (2 независимых порта чтения/записи). BRAM может функционировать в режимах WRITE_FIRST (сквозной записи) и в режиме NO_CHANGE (без изменений). Режим READ_FIRST (сначала чтение) не реализован.

Рис. 11. Блочная память BRAM
Технические характеристики BRAM приведены в таблице 2 и иллюстрируются на рис. 11.
|
Величина |
Значение |
|
Объем |
80 кбит |
|
Организация |
2К×40, 2К×36, 2К×32, 4К×20, 4К×18, 4К×16, 8К×10, 8К×9, 16К×5, 6К×4, |
|
Производительность |
750 МГц |
|
Физическая реализация |
В колонках по всей микросхеме |
|
Число портов |
Двухпортовая с независимым чтением и записью |
|
Доступ к порту |
Синхронный |
Организация
Организация каждого порта блока памяти RAM может быть независимо сконфигурирована. Возможные организации форматов блоков перечислены в таблице 2. При этом у одного и того же блока памяти организация разрядности портов может быть различная, а общий объем памяти, доступной по каждому из портов, должен быть одинаковым.
Работа
Операции чтения и операции записи памяти выполняются как синхронные. Каждый порт способен работать на своей тактовой частоте. Для большего быстродействия может быть включен дополнительный выходной регистр. Однако включение выходного регистра добавит дополнительный цикл задержки при чтении. Каждый сигнал разрешения записи (wea/web) управляет записью 10‑разрядного слова, а набор из четырех сигналов разрешения используется для записи 20 или 40 битов. Начальное значение содержания памяти определяется пользователем, или с помощью соответствующих параметров, или в файле инициализации памяти. Начальные значения выходных регистров по инициализации или по сбросу могут также быть определены пользователем. Значения по сбросу не зависят от начального значения памяти, которое было при включении питания. Параметры porta_write_mode/portb_write_mode определяют значение выходных данных порта во время операции записи. Когда porta_write_mode/portb_write_mode устанавливается в write_first, то douta/doutb устанавливается в значение, которое пишется на линиях порта dina/dinb во время операции записи. Установка porta_write_mode/portb_write_mode в значение no_change сохраняет неизменные значения на линиях порта douta/doutb во время операции записи в porta/portb.
Встроенный контроллер FIFO
У каждого блока BRAM есть встроенный контроллер FIFO. Каждый FIFO способен работать с двумя независимыми портами, у каждого из них есть свой вход сигналов тактовой частоты. На эти входы могут быть поданы одни и те же сигналы тактовой частоты, или они могут работать от разных сигналов тактовой частоты, асинхронно друг относительно друга.
Коррекция ошибок
BRAM имеет встроенные аппаратные средства контроля и исправления ошибок (ECC), позволяющие устранять однобитовые ошибки и обнаруживать двухбитовые ошибки в 32‑разрядной шине данных. Внутренняя схема устранения ошибки действует как в режиме RAM, так и в режиме FIFO. Реализация пользователем битов четности или кодов коррекции ошибки (ECC) для 32‑разрядной шины данных требует дополнительных 8 битов, что в сумме приводит к 40‑разрядной шине. Однако эти служебные биты могут использоваться и в других целях, таких как тегирование, функции управления и т. д.
Локальная RAM (LRAM)
Локальная RAM (LRAM640) реализована как 640‑битовый блок памяти с одним портом записи и одним портом чтения. Тактовые цепи для портов записи и чтения — раздельные. Блоки LRAM находятся в специальных отдельных столбцах и равномерно распределены по всей площади кристалла. Каждый блок LRAM — это отдельный 640‑битовый блок выделенной памяти. Все функции LRAM приведены в таблице 3. Порты LRAM изображены на рис. 12.

Рис. 12. Локальная RAM (LRAM640)
|
Величина |
Значение |
|
Размер блока |
640 бит |
|
Организация |
64×10 |
|
Производительность |
750 МГц |
|
Физическая реализация |
Столбцы по всей микросхеме |
|
Число портов |
Двухпортовый режим (одна шина на чтение, одна шина на запись) или однопортовый режим (один порт чтения-записи) |
|
Доступ к порту |
Синхронный по записи, синхронный или асинхронный по чтению |
Организация
Память LRAM640 может быть сконфигурирована либо как простая двухпортовая память 64×10 (один порт записи, один порт чтения), либо как однопортовая память 64×10 (один порт чтения/записи).
Инициализация и сброс
По умолчанию содержание памяти LRAM640 не определено. Если пользователь хочет, чтобы начальное содержание памяти было определено, то начальное содержимое блочных RAM может быть загружено во время конфигурации устройства. Это состояние может быть определено параметрами MEM_INIT при проектировании или же прочитано из инициализационных файлов при создании загрузочного файла. При аппаратном сбросе содержание RAM не изменяется.
Работа
У LRAM640 есть синхронный порт записи. Порт чтения может быть сконфигурирован или для асинхронных, или для синхронных операций чтения. У вывода порта чтения есть свой регистр, однако выходные сигналы могут быть направлены в обход этого регистра.
Память организуется с прямым порядком расположения байтов (little-endian), так что бит 0 отображается как нулевой разряд параметра mem_init и бит 639 отображается как бит 639 из параметра mem_init.
Применение
Локальную RAM удобно применять в качестве FIFO небольшого размера для согласования потоков данных. Такой подход позволяет существенно экономить блочную память. Также эту память можно использовать как своего рода супер-LUT-ячейку.
Умножители-аккумуляторы (BMACC56)
Умножение с накоплением — важная часть цифровой обработки сигналов в реальном времени (DSP), широко используемая для цифровой фильтрации при обработке изображений. Блок умножителя-аккумулятора (BMACC56) реализован как знаковый умножитель 28×28 и способен работать на частотах до 750 МГц. Каждый такой умножитель имеет и дополнительный блок аккумулятора. Результат умножения приводится к 56‑разрядному результату. А это позволяет производить вычисления с очень большой точностью. Результат умножения подается или на 56‑разрядный аккумулятор, или непосредственно на выход, в обход аккумулятора. Основные характеристики приводятся в таблице 4.
|
Величина |
Значение |
|
Тип арифметики |
Знаковые вычисления |
|
Производительность |
750 МГц |
|
Разрядность множителей |
28×28 |
|
Разрядность аккумулятора |
56 |
|
Разрядность цепи каскадирования |
56 |
Микросхемы Speedster22i HD имеют достаточно много блоков BMACC56, также расположенных в столбцах. У каждого блока BMACC56 есть 56‑разрядный каскадный путь, соединяющий смежные (северные/южные) блоки BMACC56. Внутренняя блок-схема показана на рис. 13.

Рис. 13. Блок-схема умножителя-аккумулятора (BMACC56)
Цепи синхронизации и сброса
Глобальная сеть тактовой частоты
У микросхем Speedster22iHD есть две иерархические сети сигналов тактовых частот: глобальная сеть и прямая (direct) сеть. У обеих сетей есть общие входные источники: непосредственно входные контакты сигналов тактовых частот и выводы PLL, которые составляют глобальный генератор сигналов тактовой частоты (GCG). На GCG обычно производится восстановление частоты из данных, поступающих на SerDes, и сигналов тактовых частот, поступающих от GPIO.
Эти входные сигналы направляются в «северную» и «южную» стороны кристалла и от них синхронизируется ядро ПЛИС. Глобальная сеть сигналов тактовых частот представляет собой сбалансированное дерево распределения сигналов, которое обеспечивает распределение этих сигналов ко всем узлам микросхемы.
Сигналы тактовых частот направляются через коммутатор к центру микросхемы, а оттуда — во все домены синхрочастот и на «западных», и на «восточных» частях микросхемы. На рис. 14 показан высокоуровневый пример маршрутизации и путей соединения для глобальной сети сигналов тактовых частот.

Рис. 14. Глобальная сеть сигналов тактовых частот
Прямая сеть тактовой частоты
Прямая сеть тактовой частоты — система распределения импульсов, предусматривающая намного более низкую задержку сигналов тактовой частоты, что особенно полезно для сложных проектов, которые используют множество сигналов тактовых частот, и тогда, когда требуется, чтобы сигналы тактовых частот были сгенерированы внутри микросхемы и перераспределены к определенным частям ПЛИС. Для прямой сети каждое ответвление сигналов тактовой частоты ограничивается только областью этих сигналов тактовых частот, как это показано на рис. 15.

Рис. 15. Прямая сеть сигналов тактовых частот
Компоненты сети сигналов тактовых частот
Сеть сигналов тактовых частот в ядре микросхемы состоит из следующих стандартных блоков:
- Верхние и нижние сигналы тактовых частот попадают на концентратор-мультиплексор, где выбирается ряд сигналов тактовых частот, приходящих из той части входных источников сигналов тактовых частот ПЛИС, как отмечалось ранее.
- В центре микросхемы находится концентратор сигналов, позволяющий мультиплексировать различные сигналы тактовых частот, приходящие из нижней и верхней части микросхемы, и вместе с ними те сигналы, которые были сгенерированы при коммутации данных. Концентратор-мультиплексор распределяет сигналы тактовых частот во все области микросхемы.
- Особые регионы сигналов тактовых частот: половина «восточной» области микросхемы и половина «западной» области микросхемы. Обе эти области сигналов тактовых частот содержат узел регионального менеджера сигналов тактовых частот (RCM), который выбирает требуемый сигнал из входящих прямых и глобальных сигналов тактовых частот и распределяет их столбцами в пределах той же области сигналов тактовых частот в ПЛИС. Высокоуровневая блок-схема компонентов сети сигналов тактовых частот и более подробный вид области сигналов тактовых частот показаны на рис. 16 и 17.
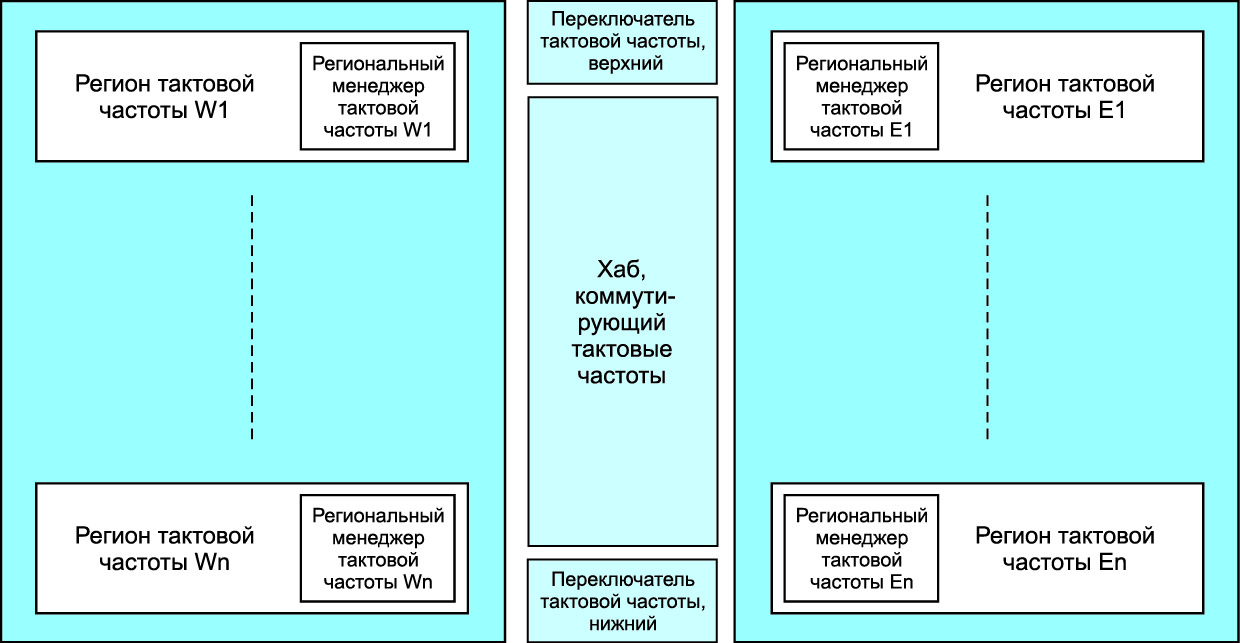
Рис. 16. Базовая блок-схема сети сигналов тактовых частот

Рис. 17. Подробный вид области сигналов тактовых частот
Источники тактовой частоты
Три источника сети сигналов тактовых частот — глобальные генераторы сигналов тактовых частот (GCGs), сигналы тактовых частот, восстановленные из входных данных в SerDes, и сигналы тактовых частот, приходящие от GPIO.
В микросхеме есть четыре GCG — по одному в каждом углу микросхемы. Каждый GCG содержит шесть глобальных буферов ввода/вывода синхрочастоты (CB) и четыре блока PLL. Буферы сигналов тактовых частот могут использоваться или в качестве трех дифференциальных входов I/O, или в качестве шести несимметричных входов I/O. Если входы I/O не используются как буферы для сигналов тактовых частот, то они могут быть назначены в качестве универсальных входов или выходов.
Блоки PLL (рис. 18) имеют низкий джиттер, широкий диапазон для входных сигналов, несколько выходов с независимыми значениями для фазы в выходном сигнале. Выходные сигналы PLL могут с частотой до 1066 МГц быть предназначены для работы ядра схемы.

Рис. 18. Блок-схема PLL
Блок-схема показывает высокоуровневое представление архитектуры PLL.
Опорный сигнал тактовой частоты, в качестве которой может использоваться частота, поступающая либо от глобального буфера сигнала тактовой частоты либо от другого GCG, делится на делителе опорной тактовой частоты (6‑разрядный делитель имеет коэффициент деления: 1–63) и затем подается на PFD. VCO генерирует восемь сигналов с одинаково разделенными фазами, один из них отправляется на делитель обратной связи через мультиплексор, что позволяет PLL работать без дополнительных задержек. Все восемь сигналов отправляются к 4 фазовращающим устройствам, которые могут независимо выбрать одну из восьми фаз. Для этого применяется выходной делитель (6‑разрядный делитель имеет коэффициент деления: 1–63), с выходов которого сигналы подаются обратно в блок PLL.
Для одного из 4 выходных сигналов тактовой частоты есть опция — этот сигнал подается на делитель обратной связи для компенсации задержки для данного сигнала после прохождения через дерево распределения сигнала тактовой частоты. У делителя обратной связи есть два режима работы: целочисленный режим, предлагающий коэффициенты от 2 до 255; дробный режим с разрешением 16 разрядов. В дробном режиме целочисленный диапазон делителя ограничивается 8–254.
Характеристики PLL представлены в таблице 5.
|
Характеристики работы |
Описание |
|
Полоса пропускания |
Отслеживание пропускной способности между 1/10 и 1/8 от частоты clk |
|
Делитель обратной связи |
8 бит (2–255). |
|
После-делитель |
6 бит |
|
Делитель опорной синхрочастоты |
6 бит |
|
Число после-делителей |
4 |
|
Поддержка дробной выходной частоты |
PLL работает с 16-разрядной точностью в режиме дробной выходной частоты |
|
Spread Spectrum — распределенный спектр частот |
Нет |
|
Задержка сигнала обратной связи (максимальная) |
Половина периода разделенной синхрочастоты |
|
Режим работы |
Нормальный Обход Пониженного энергопотребления Сброс |
|
Внутреннее разделение фаз |
12,5% периода выходного импульса |
|
Внутренняя точность фазы |
±3,5% периода выходного импульса при 2 ГГц |
|
Выходная точность фазы |
±5% периода выходного импульса при 2 ГГц |
|
Число выбираемых фаз |
8 (для каждой выходной синхрочастоты PLL можно выбрать или изменить на одну из этих восьми фаз динамически, без сбоя) |
|
Максимальное изменение рабочего цикла |
(50 ±2)% |
|
Статическая ошибка фазы |
±80 пс |
|
Джиттер — период |
±4% p2p периода выходного импульса |
|
Джиттер — от цикла до цикла |
5ps (целочисленный режим делителя, типичное значение) |
|
Джиттер — долгосрочный |
100 пс/sigma (худший случай) |
|
Время захвата |
500 периодов опорной синхрочастоты (целочисленный режим) 1000 периодов опорной синхрочастоты (дробный режим) |
|
Сброс divide-by-1 диапазона выходной частоты |
30–50 МГц |
Для сигналов тактовых частот, сгенерированных в SerDes, для каждого SerDes есть свой собственный опорный сигнал тактовой частоты и своя собственная пара PLL:
- блок PLL передачи, который синтезирует сигнал тактовой частоты передачи данных Tx непосредственно из опорного сигнала тактовой частоты и затем более медленную частоту для передачи слов данных;
- блок PLL приема, который синтезирует сигнал тактовой частоты приема данных Rx и соответствующую частоту для приема слов данных.
Таким образом, каждая линия SerDes обеспечивается двумя линиями импульсов, синхронизирующих передачу слов данных к ядру ПЛИС.
Синхроимпульсы также могут быть получены от данных, приходящих в GPIO байтами. Синхроимпульсы, которые передаются по дифференциальным линиям связи, пропускаются через мультиплексор и концентратор, и для них рекомендуется использовать или глобальные, или прямые сети сигналов тактовой частоты.
Сигналы тактовой частоты для byte-lane в ПЛИС Speedster22i передаются по 12 буферам ввода/вывода. Два из этих буферов могут применяться для приема или передачи сигнала тактовой частоты. Эти буферы могут использоваться в качестве одной дифференциальной пары для сигнала тактовой частоты или как два буфера однополярного сигнала для двух сигналов тактовых частот. Каждые из полученных сигналов тактовой частоты могут дополнительно быть задержаны с помощью DLL.
Сеть сигналов тактовой частоты Byte-Lane поддерживает одинаковые четырехбайтовые линии. Например, есть три сети сигналов тактовой частоты Byte-Lane в банке ввода/вывода с 12 байтами: 0–3, 4–7 и 8–11. Каждая сеть сигналов тактовой частоты Byte-Lane может функционировать следующим образом:
- восемь по 9 сетей сигналов тактовой частоты;
- четыре по 18 сетей сигналов тактовой частоты;
- одна по 36 сетей сигналов тактовой частоты.
Ресурсы цепи сброса
В этом разделе хочется добавить немного лирики. Если до сих пор мы говорили об обычных LUT, умножителях и пр., то вот раздел об организации сброса в микросхеме Speedster22i заслуживает особого внимания. Выше автор ссылался на высказывания Наполеона о том, что всегда побеждают «большие батальоны». Так вот, в этом разделе описания видно, что разработчики микросхемы не пошли проторенным путем. Для реализации цепей сброса они задействовали гораздо больше ресурсов, чем это обычно делается. Да, наверное, на частотах в 750 МГц количество неизбежно должно было перерасти в качество. Так и здесь в дело введены дополнительные ресурсы — «большие батальоны». И они точно победили!
В каждом углу микросхемы Speedster22i есть отдельные входные аппаратные блоки сброса, на которые заводятся сигналы сброса. Эти блоки получают как внешние сигналы сброса, поступающие на входы, так и сгенерированные в самом устройстве внутренние сигналы. Внешние входы сброса могут управляться выделенными входами сигналов тактовых частот, так же как некоторыми GPIO, расположенными в северо-восточной, юго-восточной, северо-западной или юго-западной стороне микросхемы.
Внутренние входы сбросов формируются из принятых данных и сигналов тактовых частот в логической структуре. Сигналы, поступающие к входному блоку сброса, пришедшие внешне или сгенерированные внутренне, обязаны быть активны при низком уровне и не должны иметь сбоев или глитчей. Входные сигналы могут быть или асинхронными, или синхронными. А теперь внимательно читаем дальше! Асинхронный сброс аппаратно синхронизируется по заднему фронту этого сигнала в каждом домене сигналов тактовых частот, где этот сигнал используется. Конечно, синхронный сброс не нужно синхронизировать в том же домене сигналов тактовых частот, но он синхронизируется, когда используется в любом другом домене синхрочастоты, несинхронном с текущим доменом синхрочастоты. Это позволяет полностью прекратить дискуссии о том, какой сброс лучше: асинхронный или синхронный. И снимает головную боль от метастабильности, от перетактовки сигналов при большом числе клоковых доменов. В целом это напоминает известный сюжет с микроконтроллерами, когда раньше приходилось для каждого прерывания ассемблерными командами производить сохранение контекста в стеке. А сегодня передовые микроконтроллеры делают это автоматически при обработке прерывания, избавляя разработчика от излишних проблем.
Распределение сброса
Сигналы сброса должны быть распределены как по блокам ядра ПЛИС, так и по кольцу I/O, которое включает GPIO, SerDes и аппаратные IP. Для сети сброса в ПЛИС нет какой-либо выделенной структуры, поэтому распределение сигналов сброса по ядру обычно выполняют, используя ресурсы сети сигналов тактовых частот.
Для кольца I/O фактически есть выделенная 16‑битовая шина сброса, которая гарантирует сбалансированную задержку при выдаче и снятии сброса во всем устройстве. Это делается следующим образом: распределение сброса обрабатывается конвейерно, с помощью той синхрочастоты, с которой синхронизируется сброс.
У каждой стороны микросхемы есть две группы сигналов сброса, работающие в противоположных направлениях. Каждая группа состоит из восьми сигналов сброса, охватывая всю микросхему конвейерным способом. Две группы сигналов сброса имеются в каждом банке ввода/вывода или логическом блоке (например, в контроллере DDR или в SerDes) и используют конфигурируемый конвейерный мультиплексор с конфигурируемой конвейерной задержкой. Конфигурация устанавливается для каждого мультиплексора индивидуально, чтобы сбалансировать задержку для каждого сигнала сброса во всей микросхеме. Выводы конвейерного мультиплексора впоследствии распределяются по сети сброса в банках I/O и логических блоках (рис. 19).
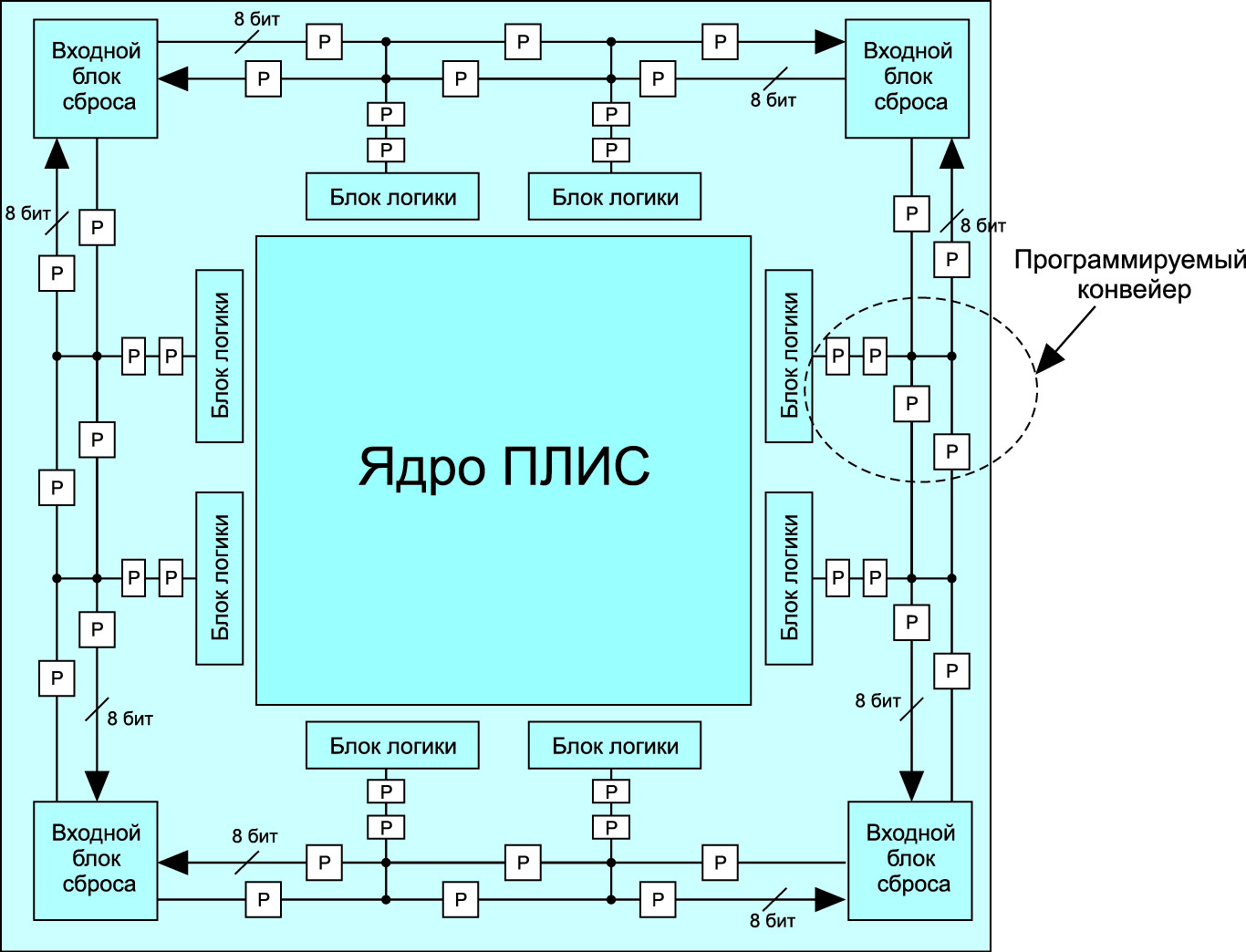
Рис. 19. Кольцевая сеть сброса для ввода/вывода
Заключение
Итак, мы ознакомились с первой из статей, посвященных новым микросхемам семейства Speedster22i HD, работающим на максимальной частоте 750 МГц и имеющим 1,7 млн LUT. Они выполнены по 22‑нм техпроцессу на фабрике Intel и предназначены для Hi-End-устройств.
Диапазон применения микросхем семейства Speedster22i HD чрезвычайно широк — от изделий для телекоммуникации до медицины. И именно наличие этих микросхем в высокоскоростных устройствах обработки и передачи данных позволит разработчикам создавать самые современные изделия для различных применений, удовлетворяющие самым жестким требованиям по скоростям обработки информации.
В следующих статьях цикла мы рассмотрим основную «изюминку» ПЛИС Speedster — аппаратные IP-ядра, цепи ввода/вывода, а также средства разработки и стартовые наборы.
Автор выражает благодарность сотрудникам представительства Achronix Russia Святославу Лисину и Владимиру Викулину за предоставленную помощь, справочные материалы и демонстрацию работы ПЛИС Speedster22i HD1000 в составе отладочной платы.
- http://en.wikipedia.org/wiki/SiliconBlue_Technologies
- http://www.eejournal.com/archives/articles/20130226‑achronix /ссылка устарела/
- www.achronix.com
- www.achronix.ru /ссылка устарела/
- http://ru.wikipedia.org/wiki/Achronix
- http://www.achronix.com/wp-content/uploads/docs/Speedster22iHD_FPGA_Family_DS004.pdf /ссылка устарела/
 17 января, 2022
17 января, 2022 4 августа, 2020
4 августа, 2020 23 мая, 2022
23 мая, 2022